
Lesson and Rule
Before you start web scraping, I would like to share what I thought to be important knowledge and rules about it:
- There is no such thing as one-size fit all codes for web scraping
- Websites are dynamic; that means your script that are working now might not be working later
- While the act of scraping is legal, the data we may extract can be illegal to use. Be sure to check this article to learn about Term and Condition
- Generally speaking, some sites allow web scrapping but there could be a limitation. Do read a website's terms and conditions or contact the site owner
Beautiful Soup
You can find installation guide and quick start at BeautifulSoup document. Here, I will present my version of tutorial.
Part 1 - HTML
Before we jump into web scraping, let’s take a quick tour through HTML for it's imperative to familiar with DOM and inheritance of web structure. You may skip Part 1 if you are familiar with the structure of a web page.
HTML consists of elements called tags. The most basic tag is the<html> tag. The html tag will consist <head> and <body>
The <head> tag contains some heading elements such as title of the page, metadata, logo, author's name, and other elements.
In this example, there is a <title> tag. The main content of the web page goes into the body tags.
As you can see, there are <p> in the body. They represent the paragraph.
<html>
<head>
<title>
Title of the page
</title>
</head>
<body>
<p>
First paragraph!
</p>
<p>
Second paragraph!
</p>
</body>
</html>
In a web browser, this HTML file will look like this:
First paragraph!
Second paragraph!
This hierarchy can be visualized as a tree, branching out from the root.
Figure 1 shows the document tree structure of a very simple XHTML document.
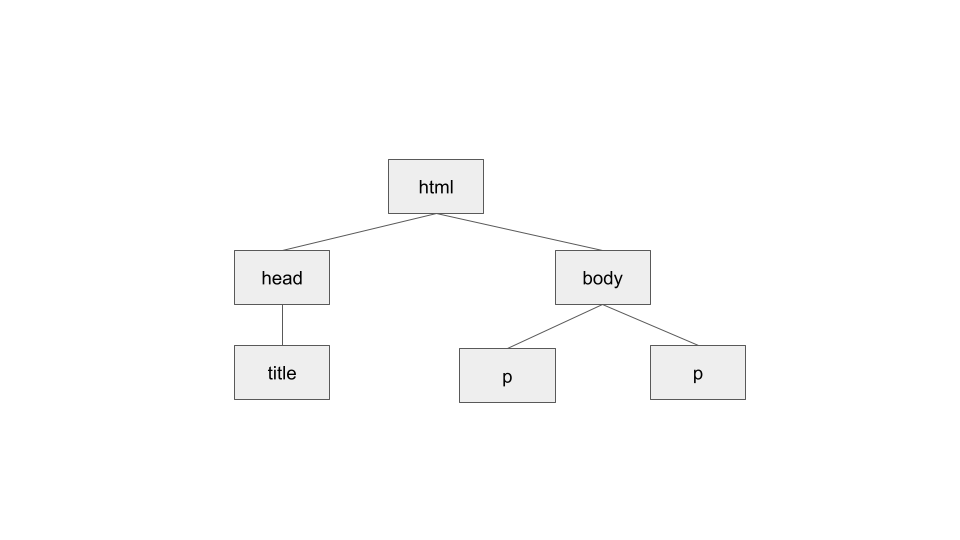
- Child — a child is a tag inside another tag. The two
ptags above are both children of thebodytag. Thetitleis child of the header - Parent — a parent is the tag another tag is inside. Above, the
htmltag is the parent of thebodyandheadtag. Thebodyis parent ofp - Sibling — a sibiling is a tag that is nested inside the same parent as another tag. For example, head and body are siblings since they are at same level and their parent is
html. Bothptags are siblings whiletitleis not siblings of them because they don't share the same parent - Descendent - any element that is connected but lower down the document tree - no matter how many levels lower. All elements that are connected below the
htmlare descendants of thathtml
Part 2 - Get Started in Python
If you need to learn about Python: Python Tutorial for Beginners
Parsing content with BeautifulSoup
---------------------- Method 1 - Without html file -----------------------------------------
html_doc = "<html> <body> <b>
<!--Hey, buddy. Want to buy a used parser?-->
</b> </body> </html>"
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'lxml')
----------------------- Method 2 - Local html file --------------------------------------------
file = open("example.html", "r")
contents = file.read()
from bs4 import BeautifulSoup
soup = BeautifulSoup(contents, 'lxml')
----------------------- Method 3 - Download page content from a website ----------------------
from bs4 import BeautifulSoup
import requests
page = requests.get("http://example.com/")
soup = BeautifulSoup(page.content, 'lxml')
Part 3 - Initial Website Extracting
Let's use http://example.com/ as our page content
To inspect the page's web element, you may use the Chrome DevTools
You can start the developer tools in Chrome by clicking View -> Developer -> Developer Tools.
from bs4 import BeautifulSoup
import requests
page = requests.get("http://example.com/")
soup = BeautifulSoup(page.content, 'lxml')
print(soup.prettify())
# This output is similar to what you see on Chrome Devtool too
------------------------------------------- Output ----------------------------------------------------
<!DOCTYPE html>
<html>
<head>
<title>
Example Domain
</title>
<meta charset="utf-8"/>
<meta content="text/html; charset=utf-8" http-equiv="Content-type"/>
<meta content="width=device-width, initial-scale=1" name="viewport"/>
<style type="text/css">
body {
background-color: #f0f0f2;
margin: 0;
padding: 0;
font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans", "Helvetica Neue", Helvetica, Arial, sans-serif;
}
div {
width: 600px;
margin: 5em auto;
padding: 2em;
background-color: #fdfdff;
border-radius: 0.5em;
box-shadow: 2px 3px 7px 2px rgba(0,0,0,0.02);
}
a:link, a:visited {
color: #38488f;
text-decoration: none;
}
@media (max-width: 700px) {
div {
margin: 0 auto;
width: auto;
}
}
</style>
</head>
<body>
<div>
<h1>
Example Domain
</h1>
<p>
This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.
</p>
<p>
<a href="https://www.iana.org/domains/example">
More information...
</a>
</p>
</div>
</body>
</html>
Part 4 - Variety of Ways to Extract Data
# Get a child tag
soup.head.title
<h1>
Example Domain
</h1>
# Check the length of content
len(soup.contents)
3
# Get content from a tag
soup.p
<p>
This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.
</p>
# Find content from a tag
soup.find('p')
<p>
This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.
</p>
# Get the text from a tag
soup.p.get_text()
This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.
# Find all that tag in the document
soup.find_all('p')
<p>
This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.
</p>
<p>
<a href="https://www.iana.org/domains/example">
More information...
</a>
</p>
# Access that specific tag with array indexing
soup.find_all('p')[1]
<p>
<a href="https://www.iana.org/domains/example">
More information...
</a>
</p>
# You may also print them with a for loop
for p in soup.find_all('p')
print(p)
<p>
This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.
</p>
<p>
<a href="https://www.iana.org/domains/example">
More information...
</a>
</p>
# Getting the child of second sibling
soup.find_all('p')[1].a
<a href="https://www.iana.org/domains/example">
More information...
</a>
# Return list of objects similar to select and select_all
soup.select("div")
div>
<h1>
Example Domain
</h1>
<p>
This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.
</p>
<p>
<a href="https://www.iana.org/domains/example">
More information...
</a>
</p>
</div>
# You can go down further
soup.select("div p a")
<a href="https://www.iana.org/domains/example">
More information...
</a>
# As long as you know the hierarchy. You also can extract data like this:
soup.select("div p a")[0].get_text()
More information...
soup.select("div p a")[0]['href']
https://www.iana.org/domains/example
I hope this is enough to digest. I did not cover all use cases but if you want to learn more about them. There are plenty of resources on the official site.
Bonus - Some Niche Tricks
What if I want to open a local example.html file then modify and add new content?
----------------------- Before -----------------------------
<html>
<body>
<p>
Add the example link
</p>
</body>
</html>
------------------------ Code ------------------------------
# Open html and read
file = open("example.html", "r")
contents = file.read()
soup = BeautifulSoup(contents, 'lxml')
# Add new tag
new_tag = soup.new_tag("a", href="http://www.example.com")
new_tag.string = 'example'
soup.p.append(new_tag)
# Modify a tag
soup.p.string = 'Changed to a new paragraph'
# Remember to write and close it otherwise it won't save it
with open('example.html', 'w') as file:
file.write(soup)
file.close()
----------------------- Result -------------------------
<html>
<body>
<p>
Changed to a new paragraph
<a href="http://www.example.com">
example
</a>
</p>
</body>
</html>
Sometimes you will encounter a tag that contains more than one string
# Example 1 - Use .strings
for string in soup.strings:
print(repr(string))
"The first string"
'\n'
'\n'
"The second string"
'\n'
# Example 2 - As you can see these strings have a lot of extra whitespace
# You can remove by using the .stripped_strings
for string in soup.stripped_strings:
print(repr(string))
"The first string"
"The second string"
You could also use .replace('\n', '') or regex in some cases
Convert HTML character to entity or entity to HTML character
import html
from bs4 import BeautifulSoup
soup = BeautifulSoup(contents, 'lxml')
# Must prettify it, otherwise it wont work
entity_format = html.escape(soup.prettify())
# Revert back
character = html.unescape(entity_format)
Get current page source with Selenium web driver
from selenium import webdriver
from bs4 import BeautifulSoup
driver = webdriver.Chrome()
# Navigate to url and get current page source for b4soup
driver.get("http://www.example.com")
page_source = driver.page_source
soup = BeautifulSoup(page_source, 'lxml')
# Question: Why don't we just parsing the exact URL with beautiful Soup without using Selenium?
# Answer : Some websites prevent web crawling, and this is one of the ways to get the page content